目录
在对 PyIntObject
整数对象 PyIntObject long
在变长对象中, 实际上还可以分为可变对象和不可变对象。 可变对象维护的数据在对象被创建后还能变化, 比如一个 list string tuple
在 Python 中, PyStringObject PyStringObject PyStringObject PyStringObject PyStringObject PyStringObject dict PyStringObject
[Include/stringonject.h]
typedef struct {
PyObject_VAR_HEAD
long ob_shash ;
int ob_sstate ;
char ob_sval [ 1 ];
/* Invariants:
* ob_sval contains space for 'ob_size+1' elements.
* ob_sval[ob_size] == 0.
* ob_shash is the hash of the string or -1 if not computed yet.
* ob_sstate != 0 iff the string object is in stringobject.c's
* 'interned' dictionary; in this case the two references
* from 'interned' to this object are *not counted* in ob_refcnt.
*/
} PyStringObject ;
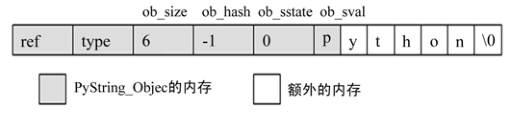
在 PyStringObject PyStringObject PyObject_VAR_HEAD ob_size PyStringObject ob_sval ob_sval ob_size
同 C 中的字符串一样, PyStringObject ob_size PyStringObject \0 \0 ob_sval ob_size + 1 ob_sval[ob_size] == '\0'
PyStringObject ob_shash PyStringObject ob_shash -1 dict
[Objects/stringobject.c]
static long
string_hash ( PyStringObject * a )
{
register Py_ssize_t len ;
register unsigned char * p ;
register long x ;
if ( a -> ob_shash != -1 )
return a -> ob_shash ;
len = a -> ob_size ;
p = ( unsigned char * ) a -> ob_sval ;
x = * p << 7 ;
while ( -- len >= 0 )
x = ( 1000003 * x ) ^ * p ++ ;
x ^= a -> ob_size ;
if ( x == -1 )
x = -2 ;
a -> ob_shash = x ;
return x ;
}
PyStringObject ob_sstate PyStringObject
下面列出了 PyStringObject PyString_Type
[Objects/stringobject.c]
PyTypeObject PyString_Type = {
PyObject_HEAD_INIT ( & PyType_Type )
0 ,
"str" ,
sizeof ( PyStringObject ),
sizeof ( char ),
string_dealloc , /* tp_dealloc */
( printfunc ) string_print , /* tp_print */
0 , /* tp_getattr */
0 , /* tp_setattr */
0 , /* tp_compare */
string_repr , /* tp_repr */
& string_as_number , /* tp_as_number */
& string_as_sequence , /* tp_as_sequence */
& string_as_mapping , /* tp_as_mapping */
( hashfunc ) string_hash , /* tp_hash */
0 , /* tp_call */
string_str , /* tp_str */
PyObject_GenericGetAttr , /* tp_getattro */
0 , /* tp_setattro */
& string_as_buffer , /* tp_as_buffer */
Py_TPFLAGS_DEFAULT | Py_TPFLAGS_CHECKTYPES |
Py_TPFLAGS_BASETYPE , /* tp_flags */
string_doc , /* tp_doc */
0 , /* tp_traverse */
0 , /* tp_clear */
( richcmpfunc ) string_richcompare , /* tp_richcompare */
0 , /* tp_weaklistoffset */
0 , /* tp_iter */
0 , /* tp_iternext */
string_methods , /* tp_methods */
0 , /* tp_members */
0 , /* tp_getset */
& PyBaseString_Type , /* tp_base */
0 , /* tp_dict */
0 , /* tp_descr_get */
0 , /* tp_descr_set */
0 , /* tp_dictoffset */
0 , /* tp_init */
0 , /* tp_alloc */
string_new , /* tp_new */
PyObject_Del , /* tp_free */
};
在 PyStringObject tp_itemsize sizeof(char) tp_itemsize tp_itemsize tp_itemsize ob_size tp_as_number tp_as_sequence tp_as_mapping PyStringObject
Python 提供了两条路径, 从 C 中原生的字符串创建 PyStringObject PyString_FromString
[Objects/stringobject.c]
PyObject *
PyString_FromString ( const char * str )
{
register size_t size ;
register PyStringObject * op ;
assert ( str != NULL );
size = strlen ( str );
if ( size > PY_SSIZE_T_MAX ) {
PyErr_SetString ( PyExc_OverflowError ,
"string is too long for a Python string" );
return NULL ;
}
if ( size == 0 && ( op = nullstring ) != NULL ) {
#ifdef COUNT_ALLOCS
null_strings ++ ;
#endif
Py_INCREF ( op );
return ( PyObject * ) op ;
}
if ( size == 1 && ( op = characters [ * str & UCHAR_MAX ]) != NULL ) {
#ifdef COUNT_ALLOCS
one_strings ++ ;
#endif
Py_INCREF ( op );
return ( PyObject * ) op ;
}
/* Inline PyObject_NewVar */
op = ( PyStringObject * ) PyObject_MALLOC ( sizeof ( PyStringObject ) + size );
if ( op == NULL )
return PyErr_NoMemory ();
PyObject_INIT_VAR ( op , & PyString_Type , size );
op -> ob_shash = -1 ;
op -> ob_sstate = SSTATE_NOT_INTERNED ;
Py_MEMCPY ( op -> ob_sval , str , size + 1 );
/* share short strings */
if ( size == 0 ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
nullstring = op ;
Py_INCREF ( op );
} else if ( size == 1 ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
characters [ * str & UCHAR_MAX ] = op ;
Py_INCREF ( op );
}
return ( PyObject * ) op ;
}
// 上述代码是 Python 2.5 源码,以下是书中的代码
PyObject *
PyString_FromString ( const char * str )
{
register size_t size ;
register PyStringObject * op ;
// [1]: 判断字符串长度
size = strlen ( str );
if ( size > PY_SSIZE_T_MAX ) {
return NULL ;
}
// [2]: 处理 NULL string
if ( size == 0 && ( op = nullstring ) != NULL ) {
return ( PyObject * ) op ;
}
// [3]: 处理字符
if ( size == 1 && ( op = characters [ * str & UCHAR_MAX ]) != NULL ) {
return ( PyObject * ) op ;
}
/* Inline PyObject_NewVar */
// [4]: 创建新的 PyStringObject 对象, 并初始化
op = ( PyStringObject * ) PyObject_MALLOC ( sizeof ( PyStringObject ) + size );
PyObject_INIT_VAR ( op , & PyString_Type , size );
op -> ob_shash = -1 ;
op -> ob_sstate = SSTATE_NOT_INTERNED ;
Py_MEMCPY ( op -> ob_sval , str , size + 1 );
/* share short strings */
if ( size == 0 ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
nullstring = op ;
Py_INCREF ( op );
} else if ( size == 1 ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
characters [ * str & UCHAR_MAX ] = op ;
Py_INCREF ( op );
}
return ( PyObject * ) op ;
}
显然传给 PyString_FromString \0 PyStringObject PY_SSIZE_T_MAX PyStringObject PY_SSIZE_T_MAX 2 147 483 647
在代码 [2] 处, 检查传入的字符串是否是一个空串, 对于空串, Python 并不是每次都会创建相应的 PyStringObject PyStringObject nullstring PyStringObject nullstring NULL PyStringObject PyStringObject nullstring PyStringObject nullstring nullstring
如果不是创建空字符串对象, 接下来的进行的动作就是申请内存, 创建 PyStringObject PyStringObject -1 SSTATE_NOT_INTERNED str PyStringObject \0 PyStringObject
图 3-1 新创建的 PyStringObject 对象的内存布局
在 PyString_FromString PyStringObject PyString_FromStringAndSize
[Objects/stringobject.c]
//[书中的代码]
PyObject * PyString_FromStringAndSize ( const char * str , Py_ssize_t size )
{
register PyStringObject * op ;
// 处理 null string
if ( size == 0 && ( op = nullstring ) != NULL ) {
return ( PyObject * ) op ;
}
// 处理字符
if ( size == 1 && str != NULL &&
( op = characters [ * str & UCHAR_MAX ]) != NULL )
{
return ( PyObject * ) op ;
}
// 创建新的 PyStringObject 对象, 并初始化
/* Inline PyObject_NewVar */
op = ( PyStringObject * ) PyObject_MALLOC ( sizeof ( PyStringObject ) + size );
if ( op == NULL )
return PyErr_NoMemory ();
PyObject_INIT_VAR ( op , & PyString_Type , size );
op -> ob_shash = -1 ;
op -> ob_sstate = SSTATE_NOT_INTERNED ;
if ( str != NULL )
Py_MEMCPY ( op -> ob_sval , str , size );
op -> ob_sval [ size ] = '\0' ;
/* share short strings */
if ( size == 0 ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
nullstring = op ;
Py_INCREF ( op );
} else if ( size == 1 && str != NULL ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
characters [ * str & UCHAR_MAX ] = op ;
Py_INCREF ( op );
}
return ( PyObject * ) op ;
}
//[代码包中的代码]
PyObject *
PyString_FromStringAndSize ( const char * str , Py_ssize_t size )
{
register PyStringObject * op ;
assert ( size >= 0 );
if ( size == 0 && ( op = nullstring ) != NULL ) {
#ifdef COUNT_ALLOCS
null_strings ++ ;
#endif
Py_INCREF ( op );
return ( PyObject * ) op ;
}
if ( size == 1 && str != NULL &&
( op = characters [ * str & UCHAR_MAX ]) != NULL )
{
#ifdef COUNT_ALLOCS
one_strings ++ ;
#endif
Py_INCREF ( op );
return ( PyObject * ) op ;
}
/* Inline PyObject_NewVar */
op = ( PyStringObject * ) PyObject_MALLOC ( sizeof ( PyStringObject ) + size );
if ( op == NULL )
return PyErr_NoMemory ();
PyObject_INIT_VAR ( op , & PyString_Type , size );
op -> ob_shash = -1 ;
op -> ob_sstate = SSTATE_NOT_INTERNED ;
if ( str != NULL )
Py_MEMCPY ( op -> ob_sval , str , size );
op -> ob_sval [ size ] = '\0' ;
/* share short strings */
if ( size == 0 ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
nullstring = op ;
Py_INCREF ( op );
} else if ( size == 1 && str != NULL ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
characters [ * str & UCHAR_MAX ] = op ;
Py_INCREF ( op );
}
return ( PyObject * ) op ;
}
PyString_FromStringAndSize PyString_FromString PyString_FromString \0 PyString_FromStringAndSize size
无论是 PyString_FromString PyString_FromStringAndSize PyString_InternInPlace
[Objects/stringobject.c]
PyObject *
PyString_FromString ( const char * str )
{
register size_t size ;
register PyStringObject * op ;
// [1]: 判断字符串长度
size = strlen ( str );
if ( size > PY_SSIZE_T_MAX ) {
return NULL ;
}
// [2]: 处理 NULL string
if ( size == 0 && ( op = nullstring ) != NULL ) {
return ( PyObject * ) op ;
}
// [3]: 处理字符
if ( size == 1 && ( op = characters [ * str & UCHAR_MAX ]) != NULL ) {
return ( PyObject * ) op ;
}
/* Inline PyObject_NewVar */
// [4]: 创建新的 PyStringObject 对象, 并初始化
op = ( PyStringObject * ) PyObject_MALLOC ( sizeof ( PyStringObject ) + size );
PyObject_INIT_VAR ( op , & PyString_Type , size );
op -> ob_shash = -1 ;
op -> ob_sstate = SSTATE_NOT_INTERNED ;
Py_MEMCPY ( op -> ob_sval , str , size + 1 );
/* share short strings */
// intern (共享) 长度较短的 PyStringObject 对象
if ( size == 0 ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
nullstring = op ;
Py_INCREF ( op );
} else if ( size == 1 ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
characters [ * str & UCHAR_MAX ] = op ;
Py_INCREF ( op );
}
return ( PyObject * ) op ;
}
PyStringObject PyStringObject PyStringObject PyObject* PyStringObject PyString_InternInPlace
[Objects/stringobject.c]
void
PyString_InternInPlace ( PyObject ** p )
{
register PyStringObject * s = ( PyStringObject * )( * p );
PyObject * t ;
if ( s == NULL || ! PyString_Check ( s ))
Py_FatalError ( "PyString_InternInPlace: strings only please!" );
/* If it's a string subclass, we don't really know what putting
it in the interned dict might do. */
if ( ! PyString_CheckExact ( s ))
return ;
if ( PyString_CHECK_INTERNED ( s ))
return ;
if ( interned == NULL ) {
interned = PyDict_New ();
if ( interned == NULL ) {
PyErr_Clear (); /* Don't leave an exception */
return ;
}
}
t = PyDict_GetItem ( interned , ( PyObject * ) s );
if ( t ) {
Py_INCREF ( t );
Py_DECREF ( * p );
* p = t ;
return ;
}
if ( PyDict_SetItem ( interned , ( PyObject * ) s , ( PyObject * ) s ) < 0 ) {
PyErr_Clear ();
return ;
}
/* The two references in interned are not counted by refcnt.
The string deallocator will take care of this */
s -> ob_refcnt -= 2 ;
PyString_CHECK_INTERNED ( s ) = SSTATE_INTERNED_MORTAL ;
}
//[上述代码是代码包中的代码,下面的是书中的代码]
void
PyString_InternInPlace ( PyObject ** p )
{
register PyStringObject * s = ( PyStringObject * )( * p );
PyObject * t ;
// 对 PyStringObject 进行类型和状态检查
if ( ! PyString_CheckExact ( s ))
return ;
if ( PyString_CHECK_INTERNED ( s ))
return ;
// 创建记录经 intern 机制处理后的 PyStringObject 的 dict
if ( interned == NULL ) {
interned = PyDict_New ();
}
// [1] : 检查 PyStringObject 对象 S 是否存在对应的 intern 后的 PyStringObject 对象
t = PyDict_GetItem ( interned , ( PyObject * ) s );
if ( t ) {
// 注意这里对引用计数的调整
Py_INCREF ( t );
Py_DECREF ( * p );
* p = t ;
return ;
}
// [2] : 在 interned 中记录检查 PyStringObject 对象 S
PyDict_SetItem ( interned , ( PyObject * ) s , ( PyObject * ) s );
/* The two references in interned are not counted by refcnt.
The string deallocator will take care of this */
// [3] : 注意这里对引用计数的调整
s -> ob_refcnt -= 2 ;
// [4] : 调整 S 中的 intern 状态标志
PyString_CHECK_INTERNED ( s ) = SSTATE_INTERNED_MORTAL ;
}
PyString_InternInPlace
intern 机制的核心在于 interned, interned 在 stringobject.c 中被定义为: static PyObject *interned
在代码中 interned 实际指向的是 PyDict_New PyDict_New PyDictObject dict map<PyObject*, PyObject*>
interned 机制的关键就是在系统中有一个 key value 映射关系的集合, 集合的名称叫做 interned。 其中记录着被 intern 机制处理过的 PyStringObject PyStringObject PyObject
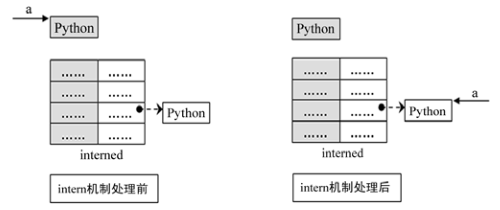
下图展示了如果 interned 中存在这样的对象 b, 再对 a 进行 intern 操作时, 原本指向 a 的 PyObject*
图 3-2 intern 机制示意图
对于被 intern 机制处理的 PyStringObject PyStringObject PyObject PyDictObject
因此 interned 中的指针不能作为 a 的有效引用。 这就是代码 [3] 处会将引用计数减 2 的原因。 在 A 的引用计数在某个时刻减为 0 之后, 系统将会销毁对象 a, 同时会在 interned 中删除指向 a 的指针, 在 string_dealloc
[Objects/stringobject.c]
static void
string_dealloc ( PyObject * op )
{
switch ( PyString_CHECK_INTERNED ( op )) {
case SSTATE_NOT_INTERNED :
break ;
case SSTATE_INTERNED_MORTAL :
/* revive dead object temporarily for DelItem */
op -> ob_refcnt = 3 ;
if ( PyDict_DelItem ( interned , op ) != 0 )
Py_FatalError (
"deletion of interned string failed" );
break ;
case SSTATE_INTERNED_IMMORTAL :
Py_FatalError ( "Immortal interned string died." );
default :
Py_FatalError ( "Inconsistent interned string state." );
}
op -> ob_type -> tp_free ( op );
}
Python 在创建一个字符串的时候, 会首先在 interned 中检查是否已经有改字符串对应的 PyStringObject PyStringObject PyString_FromString PyStringObject PyString_InternInPlace PyStringObject PyStringObject PyStringObject PyStringObject PyString_InternInPlace
Python 提供了一个以 char*
PyObject *
PyString_InternFromString ( const char * cp )
{
PyObject * s = PyString_FromString ( cp );
if ( s == NULL )
return NULL ;
PyString_InternInPlace ( & s );
return s ;
}
临时对象仍然被创建出来, 实际上在 Python 中, 必须创建一个临时的 PyStringObject PyDictObject PyObject *
实际上被 intern 机制处理后的 PyStringObject SSTATE_INTERNED_IMMORTAL SSTATE_INTERNED_MORTAL string_dealloc SSTATE_INTERNED_IMMORTAL PyStringObject
PyString_InternInPlace SSTATE_INTERNED_MORTAL PyStringObject SSTATE_INTERNED_IMMORTAL PyString_InternInPlace PyStringObject
void
PyString_InternImmortal ( PyObject ** p )
{
PyString_InternInPlace ( p );
if ( PyString_CHECK_INTERNED ( * p ) != SSTATE_INTERNED_IMMORTAL ) {
PyString_CHECK_INTERNED ( * p ) = SSTATE_INTERNED_IMMORTAL ;
Py_INCREF ( * p );
}
}
Python 为 PyStringObject PyStringObject characters
[Objects/stringobject.c]
static PyStringObject * characters [ UCHAR_MAX + 1 ];
UCHAR_MAX
这个被定义在 C 语言的 limits.h 头文件中。
在 Python 的整数对象体系中, 小整数的缓冲池是在 Python 初始化的时候被创建的, 而字符串对象体系中的字符缓冲池则是以静态变量的形式存在。 在 Python 初始化完成之后, 缓冲池中的所有 PyStringObject
创建一个 PyStringObject PyString_FromString PyString_FromStringAndSize
[Objects/stringobject.c]
PyObject *
PyString_FromStringAndSize ( const char * str , Py_ssize_t size )
{
...
else if ( size == 1 && str != NULL ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
characters [ * str & UCHAR_MAX ] = op ;
Py_INCREF ( op );
}
return ( PyObject * ) op ;
}
// 代码
PyObject *
PyString_FromStringAndSize ( const char * str , Py_ssize_t size )
{
register PyStringObject * op ;
assert ( size >= 0 );
if ( size == 0 && ( op = nullstring ) != NULL ) {
#ifdef COUNT_ALLOCS
null_strings ++ ;
#endif
Py_INCREF ( op );
return ( PyObject * ) op ;
}
if ( size == 1 && str != NULL &&
( op = characters [ * str & UCHAR_MAX ]) != NULL )
{
#ifdef COUNT_ALLOCS
one_strings ++ ;
#endif
Py_INCREF ( op );
return ( PyObject * ) op ;
}
/* Inline PyObject_NewVar */
op = ( PyStringObject * ) PyObject_MALLOC ( sizeof ( PyStringObject ) + size );
if ( op == NULL )
return PyErr_NoMemory ();
PyObject_INIT_VAR ( op , & PyString_Type , size );
op -> ob_shash = -1 ;
op -> ob_sstate = SSTATE_NOT_INTERNED ;
if ( str != NULL )
Py_MEMCPY ( op -> ob_sval , str , size );
op -> ob_sval [ size ] = '\0' ;
/* share short strings */
if ( size == 0 ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
nullstring = op ;
Py_INCREF ( op );
} else if ( size == 1 && str != NULL ) {
PyObject * t = ( PyObject * ) op ;
PyString_InternInPlace ( & t );
op = ( PyStringObject * ) t ;
characters [ * str & UCHAR_MAX ] = op ;
Py_INCREF ( op );
}
return ( PyObject * ) op ;
}
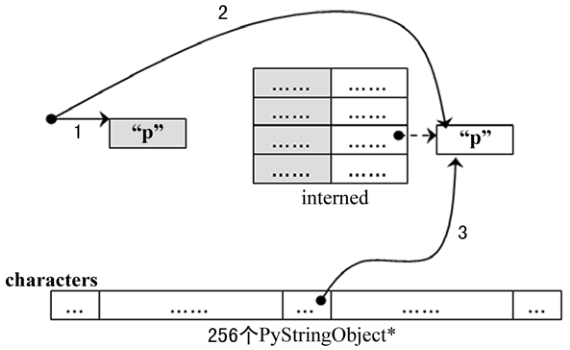
先对所创建的字符串 (字符) 对象进行 intern 操作, 在将 intern 的结果缓存到字符缓冲池 characters PyStringObject
图 3-3 创建字符对应的 PyStringObject 对象
3 条带有标号的曲线既代表指针, 有代表进行操作的顺序:
创建 PyStringObject <string p>
对对象 <string p>
将对象 <string p>
在创建 PyStringObject
[Objects/stringobject.c]
PyObject *
PyString_FromStringAndSize ( const char * str , Py_ssize_t size )
{
register PyStringObject * op ;
...
if ( size == 1 && str != NULL &&
( op = characters [ * str & UCHAR_MAX ]) != NULL )
{
return ( PyObject * ) op ;
}
...
}
Python 的字符串连接时严重影响 Python 程序执行效率, Python 通过 "+" 进行字符串连接的方法效率极其低下, 根源在于 Python 中的 PyStringObject PyStringObject PyStringObject N - 1
推荐的做法是通过利用 PyStringObject join list tuple PyStringObject
通过 "+" 操作符对字符串进行连接时, 会调用 string_concat
[Objects/stringobject.c]
static PyObject *
string_concat ( register PyStringObject * a , register PyObject * bb )
{
register Py_ssize_t size ;
register PyStringObject * op ;
if ( ! PyString_Check ( bb )) {
#ifdef Py_USING_UNICODE
if ( PyUnicode_Check ( bb ))
return PyUnicode_Concat (( PyObject * ) a , bb );
#endif
PyErr_Format ( PyExc_TypeError ,
"cannot concatenate 'str' and '%.200s' objects" ,
bb -> ob_type -> tp_name );
return NULL ;
}
#define b ((PyStringObject *)bb)
/* Optimize cases with empty left or right operand */
if (( a -> ob_size == 0 || b -> ob_size == 0 ) &&
PyString_CheckExact ( a ) && PyString_CheckExact ( b )) {
if ( a -> ob_size == 0 ) {
Py_INCREF ( bb );
return bb ;
}
Py_INCREF ( a );
return ( PyObject * ) a ;
}
// 计算字符串连接后的长度 size
size = a -> ob_size + b -> ob_size ;
if ( size < 0 ) {
PyErr_SetString ( PyExc_OverflowError ,
"strings are too large to concat" );
return NULL ;
}
/* Inline PyObject_NewVar */
// 创建新的 PyStringObject 对象 , 其维护的用于存储字符的内存长度为 size
op = ( PyStringObject * ) PyObject_MALLOC ( sizeof ( PyStringObject ) + size );
if ( op == NULL )
return PyErr_NoMemory ();
PyObject_INIT_VAR ( op , & PyString_Type , size );
op -> ob_shash = -1 ;
op -> ob_sstate = SSTATE_NOT_INTERNED ;
// 将 a 和 b 中的字符拷贝到新建的 PyStringObject 中
Py_MEMCPY ( op -> ob_sval , a -> ob_sval , a -> ob_size );
Py_MEMCPY ( op -> ob_sval + a -> ob_size , b -> ob_sval , b -> ob_size );
op -> ob_sval [ size ] = '\0' ;
return ( PyObject * ) op ;
#undef b
}
对于任意两个 PyStringObject PyStringObject join list PyStringObject
[Objects/stringobject.c]
static PyObject *
string_join ( PyStringObject * self , PyObject * orig )
{
char * sep = PyString_AS_STRING ( self );
// 假设调用 "abc".join(list) , 那么 self 就是 "abc" 对应的 PyStringObject
// 对象 , 所以 seplen 中存储着 abc 的长度 。
const Py_ssize_t seplen = PyString_GET_SIZE ( self );
PyObject * res = NULL ;
char * p ;
Py_ssize_t seqlen = 0 ;
size_t sz = 0 ;
Py_ssize_t i ;
PyObject * seq , * item ;
seq = PySequence_Fast ( orig , "" );
if ( seq == NULL ) {
return NULL ;
}
// 获取 list 中 PyStringObject 对象的个数, 保存在 seqlen 中
seqlen = PySequence_Size ( seq );
if ( seqlen == 0 ) {
Py_DECREF ( seq );
return PyString_FromString ( "" );
}
if ( seqlen == 1 ) {
item = PySequence_Fast_GET_ITEM ( seq , 0 );
if ( PyString_CheckExact ( item ) || PyUnicode_CheckExact ( item )) {
Py_INCREF ( item );
Py_DECREF ( seq );
return item ;
}
}
/* There are at least two things to join, or else we have a subclass
* of the builtin types in the sequence.
* Do a pre-pass to figure out the total amount of space we'll
* need (sz), see whether any argument is absurd, and defer to
* the Unicode join if appropriate.
*/
// 遍历 list 中每个字符串 , 累加获得 连接 list 中所有字符串后的长度
for ( i = 0 ; i < seqlen ; i ++ ) {
const size_t old_sz = sz ;
// seq为python 中的 list 对象 , 这里获取其中第 i 个字符串 。
item = PySequence_Fast_GET_ITEM ( seq , i );
if ( ! PyString_Check ( item )){
#ifdef Py_USING_UNICODE
if ( PyUnicode_Check ( item )) {
/* Defer to Unicode join.
* CAUTION: There's no gurantee that the
* original sequence can be iterated over
* again, so we must pass seq here.
*/
PyObject * result ;
result = PyUnicode_Join (( PyObject * ) self , seq );
Py_DECREF ( seq );
return result ;
}
#endif
PyErr_Format ( PyExc_TypeError ,
"sequence item %zd: expected string,"
" %.80s found" ,
i , item -> ob_type -> tp_name );
Py_DECREF ( seq );
return NULL ;
}
sz += PyString_GET_SIZE ( item );
if ( i != 0 )
sz += seplen ;
if ( sz < old_sz || sz > PY_SSIZE_T_MAX ) {
PyErr_SetString ( PyExc_OverflowError ,
"join() result is too long for a Python string" );
Py_DECREF ( seq );
return NULL ;
}
}
/* Allocate result space. */
// 创建长度为 sz 的 PyStringObject 对象
res = PyString_FromStringAndSize (( char * ) NULL , sz );
if ( res == NULL ) {
Py_DECREF ( seq );
return NULL ;
}
/* Catenate everything. */
// 将 list 中的字符串拷贝到新创建的 PyStringObject 对象中
p = PyString_AS_STRING ( res );
for ( i = 0 ; i < seqlen ; ++ i ) {
size_t n ;
item = PySequence_Fast_GET_ITEM ( seq , i );
n = PyString_GET_SIZE ( item );
Py_MEMCPY ( p , PyString_AS_STRING ( item ), n );
p += n ;
if ( i < seqlen - 1 ) {
Py_MEMCPY ( p , sep , seplen );
p += seplen ;
}
}
Py_DECREF ( seq );
return res ;
}
执行 join list PyStringObject PyStringObject list PyStringObject PyStringObject
通过在 string_concat string_join
图 3-4 concat 与 join 的区别
对 PyStringObject PyStringObject PyStringObject PyStringObject
图 3-5 intern 机制的观察结果
通过在 string_length PyStringObject PyStringObject*
观察进行缓冲处理的字符对象, 同样在 string_length len() len PyStringObject len
static Py_ssize_t
string_length ( PyStringObject * a )
{
return a -> ob_size ;
}
上述代码是 string_length
static void ShowCharacter ()
{
char chA = 'a' ;
PyStringObject ** posA = characters + ( unsigned short ) chA ;
int i ;
char value [ 5 ];
int refcnts [ 5 ];
for ( i = 0 ; i < 5 ; ++ i )
{
PyStringObject * strObj = posA [ i ];
value [ i ] = strObj -> ob_sval [ 0 ];
refcnts [ i ] = strObj -> ob_refcnt ;
}
printf ( " value: " );
for ( i = 0 ; i < 5 ; ++ i )
{
printf ( "%c \t " , value [ i ]);
}
printf ( " \n refcnt: " );
for ( i = 0 ; i < 5 ; ++ i )
{
printf ( "%d \t " , refcnts [ i ]);
}
printf ( " \n " );
}
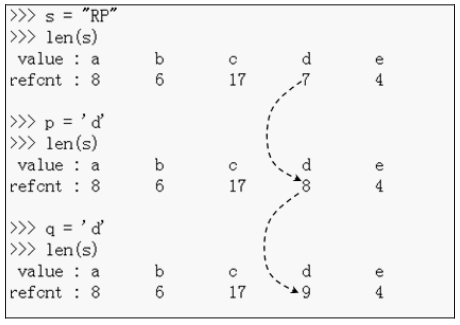
图 3-6 展示了观察的结果, 在创建字符对象时, Python 确实只使用了缓冲池里的对象, 没有创建新的对象。
图 3-6 Python 内部的字符缓冲池